
Play Text-to-Speech:
This article is an in-depth exploration of practical machine learning concepts for both beginners and experienced practitioners. This comprehensive guide delves into the foundations of machine learning, offering hands-on insights into essential techniques using the widely adopted Python libraries, Scikit-Learn and TensorFlow.
The article begins with an introduction to key machine learning principles, setting the stage for an immersive learning experience. Readers will then navigate through the process of setting up a machine learning environment, understanding the basics of data preprocessing, and exploring linear regression and classification techniques.
Moving beyond the fundamentals, the guide introduces advanced topics such as clustering, unsupervised learning, neural networks, and natural language processing. Real-world applications and deployment strategies are thoroughly covered, providing readers with the tools and knowledge needed to apply machine learning solutions in various domains.
Table of Contents:
1. Introduction to Machine Learning
- 1.1 Definition and Concepts
- 1.2 Types of Machine Learning (Supervised, Unsupervised, etc.)
- 1.3 Importance of Hands-On Learning
2. Setting Up Your Machine Learning Environment
- 2.1 Installing Python and Necessary Libraries
- 2.2 Creating a Virtual Environment
- 2.3 Introduction to Jupyter Notebooks
3. Understanding the Basics
- 3.1 Exploring Data and Data Preprocessing
- 3.2 Feature Scaling and Normalization
- 3.3 Handling Missing Data
4. Linear Regression and Beyond
- 4.1 Introduction to Regression
- 4.2 Linear Regression
- 4.3 Polynomial Regression
- 4.4 Model Evaluation Metrics
5. Classification Techniques
- 5.1 Binary and Multiclass Classification
- 5.2 Support Vector Machines (SVM)
- 5.3 Decision Trees and Random Forests
- 5.4 Model Evaluation for Classification
6. Clustering and Unsupervised Learning
- 6.1 K-Means Clustering
- 6.2 Hierarchical Clustering
- 6.3 Dimensionality Reduction with PCA
7. Introduction to Neural Networks
- 7.1 Basics of Neural Networks
- 7.2 Building a Simple Neural Network
- 7.3 Deep Learning with TensorFlow
8. Natural Language Processing (NLP)
- 8.1 Overview of NLP
- 8.2 Text Preprocessing
- 8.3 Building NLP Models
9. Recommendation Systems
- 9.1 Collaborative Filtering
- 9.2 Content-Based Recommendation
- 9.3 Hybrid Recommendation Systems
10. Model Deployment and Real-World Applications
- 10.1 Considerations for Model Deployment
- 10.2 Real-World Applications of Machine Learning
- 10.3 Challenges and Best Practices
11. Advanced Topics and Emerging Trends
- 11.1 Transfer Learning
- 11.2 Reinforcement Learning
- 11.3 Generative Adversarial Networks (GANs)
12. Practical Tips and Best Practices
- 12.1 Tips for Effective Model Training
- 12.2 Debugging and Troubleshooting
- 12.3 Continuous Learning in the Field of Machine Learning
13. Conclusion
- 13.1 Recap of Key Concepts
- 13.2 Encouragement for Further Exploration
1. Introduction to Machine Learning
Machine Learning (ML) stands as the transformative force behind the evolution of modern technology, enabling systems to learn from data and improve their performance over time. In this comprehensive article, we embark on a journey through the fundamental concepts that define the landscape of machine learning, aiming to demystify its core principles and emphasize the critical role of hands-on learning.
1.1 Definition and Concepts
At its core, machine learning is a subfield of artificial intelligence (AI) that equips systems with the ability to automatically learn and improve from experience without explicit programming. This section delves into the essential concepts that form the foundation of machine learning, providing readers with a clear understanding of key terms, processes, and the underlying mechanisms that drive learning algorithms.
- Core Concepts: Unravel the concepts of data, features, and labels. Understand the distinction between training and testing data and the iterative nature of the learning process.
- Supervised Learning: Explore the concept of supervised learning, where algorithms learn from labeled datasets to make predictions or decisions. Delve into the interplay between input and output variables, and the role of training a model to map input to output.
- Unsupervised Learning: Navigate the realm of unsupervised learning, where algorithms analyze and interpret data without labeled responses. Examine clustering and association techniques that uncover hidden patterns and structures within datasets.
- Reinforcement Learning: Introduce the concept of reinforcement learning, where systems learn by interacting with an environment and receiving feedback in the form of rewards or penalties. Understand the dynamic nature of decision-making in this paradigm.
1.2 Types of Machine Learning (Supervised, Unsupervised, etc.)
Machine learning is a diverse field encompassing various paradigms, each tailored to specific data scenarios and learning objectives. This section provides a comprehensive overview of the major types of machine learning, elucidating their distinctive characteristics and applications.
- Supervised Learning: Delve into the realm of supervised learning, where models are trained on labeled datasets, making it ideal for tasks like classification and regression. Understand the significance of training algorithms to generalize patterns in data.
- Unsupervised Learning: Explore the world of unsupervised learning, where algorithms uncover patterns and relationships within unlabeled datasets. Discuss clustering and dimensionality reduction techniques that play a pivotal role in revealing hidden structures.
- Semi-Supervised Learning: Introduce the concept of semi-supervised learning, a hybrid approach combining elements of both supervised and unsupervised learning. Understand its applications in scenarios where acquiring labeled data is challenging.
- Reinforcement Learning: Dive into the dynamic field of reinforcement learning, where agents learn through trial and error, optimizing their actions based on feedback from the environment. Discuss applications in robotics, gaming, and autonomous systems.
1.3 Importance of Hands-On Learning
In the fast-paced world of machine learning, theoretical knowledge alone is insufficient. This section underscores the paramount importance of hands-on learning in mastering the intricacies of machine learning.
- Learning by Doing: Emphasize the value of practical application in reinforcing theoretical concepts. Discuss how hands-on exercises, projects, and real-world implementations enhance comprehension and skill development.
- Enhanced Retention: Explore how actively engaging with machine learning tasks fosters better retention and a deeper understanding of algorithms, models, and methodologies.
- Problem-Solving Skills: Highlight how hands-on learning cultivates problem-solving skills, enabling practitioners to tackle real-world challenges and adapt to diverse scenarios.
- Transitioning Theory to Practice: Showcase the bridge between theory and application, illustrating how hands-on experience transforms theoretical concepts into tangible solutions.
As we embark on this exploration, the goal is not only to comprehend the intricacies of machine learning but also to cultivate the skills essential for navigating the dynamic landscape of data-driven intelligence.
2. Setting Up Your Machine Learning Environment: A Primer for Seamless Learning
Embarking on the exciting journey of machine learning demands a robust and well-configured environment. In this section, we guide you through the essential steps of setting up your machine learning environment, ensuring a smooth and efficient learning experience. From installing Python and necessary libraries to creating a virtual environment and getting acquainted with Jupyter Notebooks, we pave the way for a seamless dive into the world of machine learning.
2.1 Installing Python and Necessary Libraries
2.1.1 Python Installation
Python, being the backbone of many machine learning frameworks, serves as the first stepping stone. Follow these steps to install Python:
# For Windows and macOS
brew install python
# For Linux
sudo apt-get update
sudo apt-get install python32.1.2 Library Installation
With Python in place, install the necessary libraries using pip, the Python package installer:
pip install numpy pandas matplotlib scikit-learnThis script installs NumPy and pandas for data manipulation, matplotlib for visualization, and scikit-learn for machine learning algorithms.
2.2 Creating a Virtual Environment
2.2.1 Virtual Environment Setup
Virtual environments ensure project-specific dependencies, preventing conflicts between different projects. Use the following script to create and activate a virtual environment:
# Install virtualenv
pip install virtualenv
# Create a virtual environment
python3 -m venv myenv
# Activate the virtual environment
# For Windows
.\myenv\Scripts\activate
# For macOS/Linux
source myenv/bin/activate2.2.2 Installing Jupyter Notebooks
Jupyter Notebooks provide an interactive and visual platform for machine learning experimentation. Install Jupyter with:
pip install jupyter2.3 Introduction to Jupyter Notebooks
2.3.1 Launching Jupyter Notebooks
Once installed, start Jupyter Notebooks with the following command:
jupyter notebookThis opens a new tab in your web browser, allowing you to create and run Jupyter Notebooks.
2.3.2 Creating Your First Notebook
Click on “New” and choose “Python 3” to create a new notebook. Jupyter Notebooks are composed of cells, which can contain code or text. Write your Python code in the cells and execute them to see the results immediately.
Conclusion
By following these steps, you have established a solid foundation for your machine learning environment. Installing Python, essential libraries, setting up a virtual environment, and getting acquainted with Jupyter Notebooks are critical prerequisites for hands-on machine learning. Armed with this environment, you are ready to explore the exciting world of data science and machine learning, building and training models with confidence. Happy coding!
3. Understanding the Basics: Navigating the Foundation of Machine Learning
In the vast landscape of machine learning, a robust grasp of the basics is indispensable. In this section, we delve into the fundamental concepts that underpin machine learning, exploring data, preprocessing techniques, and addressing common challenges like missing data. This foundational knowledge sets the stage for building powerful machine learning models with confidence.
3.1 Exploring Data and Data Preprocessing
3.1.1 Loading and Inspecting Data
The journey begins with understanding the dataset. Consider the following Python script using pandas to load a dataset and obtain an initial glimpse:
import pandas as pd
# Load the dataset (replace 'your_dataset.csv' with the actual file path)
data = pd.read_csv('your_dataset.csv')
# Display the first few rows of the dataset
print(data.head())3.1.2 Data Summary Statistics
Understanding data distribution is crucial. Utilize the describe() function to obtain key statistics:
# Display summary statistics of the dataset
print(data.describe())3.2 Feature Scaling and Normalization
3.2.1 Standardization with Scikit-Learn
Feature scaling ensures that variables are on a similar scale, preventing one feature from dominating others. Use Scikit-Learn to standardize features:
from sklearn.preprocessing import StandardScaler
# Initialize the StandardScaler
scaler = StandardScaler()
# Fit and transform the data
scaled_data = scaler.fit_transform(data[['feature1', 'feature2']])3.2.2 Min-Max Scaling
Alternatively, apply Min-Max scaling to constrain features between 0 and 1:
from sklearn.preprocessing import MinMaxScaler
# Initialize the MinMaxScaler
minmax_scaler = MinMaxScaler()
# Fit and transform the data
minmax_scaled_data = minmax_scaler.fit_transform(data[['feature1', 'feature2']])3.3 Handling Missing Data
3.3.1 Identifying Missing Data
Detecting and addressing missing values is a crucial step. Pandas provides a straightforward method to identify missing data:
# Check for missing values in the dataset
print(data.isnull().sum())3.3.2 Imputing Missing Data
Impute missing data using techniques like mean or median imputation:
from sklearn.impute import SimpleImputer
# Initialize the SimpleImputer
imputer = SimpleImputer(strategy='mean')
# Fit and transform the data
imputed_data = pd.DataFrame(imputer.fit_transform(data), columns=data.columns)Conclusion
In unraveling the basics of machine learning, we’ve explored essential steps in data exploration, preprocessing, and handling missing data. Armed with the ability to load, inspect, scale, and impute data, you are better equipped to prepare datasets for machine learning models. As we journey further into the realms of algorithms and model building, remember that a strong foundation ensures the success of your machine learning endeavors. Happy exploring!
4. Linear Regression and Beyond: Unveiling the Power of Predictive Modeling
In the realm of machine learning, regression analysis stands as a cornerstone, enabling us to make predictions based on data patterns. In this section, we dive into the world of regression, starting with the fundamentals and progressing to linear and polynomial regression models. Additionally, we explore key metrics for evaluating the performance of these models.
4.1 Introduction to Regression
Regression analysis is a predictive modeling technique that investigates the relationship between a dependent variable and one or more independent variables. It’s a tool for understanding and exploiting patterns within data to make informed predictions. Regression models come in various forms, each suited to specific types of data and relationships.
4.2 Linear Regression
4.2.1 Understanding Linear Regression
Linear regression is the simplest form of regression, modeling the relationship between a dependent variable and one independent variable. The equation for a simple linear regression is given by:
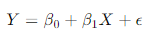
Here, ( Y ) is the dependent variable, ( X ) is the independent variable, ( beta_0 ) is the intercept, ( beta_1 ) is the slope, and ( epsilon ) is the error term.
4.2.2 Implementing Linear Regression with Scikit-Learn
Let’s implement a simple linear regression model using Scikit-Learn:
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
# Assume X and y are your independent and dependent variables
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Initialize the Linear Regression model
model = LinearRegression()
# Fit the model to the training data
model.fit(X_train, y_train)
# Make predictions on the test set
predictions = model.predict(X_test)
# Evaluate the model
mse = mean_squared_error(y_test, predictions)
print(f'Mean Squared Error: {mse}')4.3 Polynomial Regression
4.3.1 Extending to Polynomial Regression
Polynomial regression extends the linear regression model to capture non-linear relationships. The equation for a polynomial regression of degree ( n ) is given by:
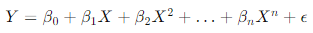
4.3.2 Implementing Polynomial Regression
Implementing polynomial regression involves transforming the features to include higher-order terms. Use Scikit-Learn’s PolynomialFeatures:
from sklearn.preprocessing import PolynomialFeatures
# Assume X is your feature matrix
poly = PolynomialFeatures(degree=2)
X_poly = poly.fit_transform(X)
# Now, apply linear regression to the transformed features
model = LinearRegression()
model.fit(X_poly, y)4.4 Model Evaluation Metrics
4.4.1 Metrics for Regression
Evaluating the performance of regression models requires metrics that quantify the difference between predicted and actual values. Common metrics include:

These metrics quantify the accuracy of predictions, providing insights into the model’s performance.
Conclusion
Mastering regression models, from linear to polynomial, is a pivotal step in predictive modeling. Armed with the knowledge of their foundations, implementation, and evaluation metrics, you can confidently embark on regression-based machine learning projects. As we advance into more complex models, remember that a solid understanding of the basics ensures success in the broader landscape of machine learning. Happy modeling!
5. Classification Techniques: Navigating the Landscape of Predictive Categorization
In the vast terrain of machine learning, classification techniques are indispensable tools for predicting categorical outcomes. In this section, we explore the foundational concepts of binary and multiclass classification, delve into the power of Support Vector Machines (SVM), and unravel the intricacies of Decision Trees and Random Forests. Additionally, we equip ourselves with essential metrics for evaluating the performance of classification models.
5.1 Binary and Multiclass Classification
5.1.1 Understanding Binary and Multiclass Classification
Classification tasks involve predicting a label or category for given input data. In binary classification, the model predicts between two classes (e.g., spam or not spam). Multiclass classification extends this to scenarios with more than two classes (e.g., classifying fruits into apples, oranges, or bananas).
5.2 Support Vector Machines (SVM)
5.2.1 The Power of Support Vector Machines
Support Vector Machines (SVM) are versatile algorithms used for both classification and regression tasks. SVM aims to find the optimal hyperplane that maximally separates data points of different classes.
5.2.2 Implementing SVM with Scikit-Learn
Let’s implement a basic SVM model using Scikit-Learn:
from sklearn.svm import SVC
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# Assume X and y are your feature matrix and labels
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Initialize the SVM model
model = SVC(kernel='linear')
# Fit the model to the training data
model.fit(X_train, y_train)
# Make predictions on the test set
predictions = model.predict(X_test)
# Evaluate the model
accuracy = accuracy_score(y_test, predictions)
print(f'Accuracy: {accuracy}')5.3 Decision Trees and Random Forests
5.3.1 The Logic of Decision Trees
Decision Trees are tree-like structures where each node represents a decision based on a particular feature. Random Forests, an ensemble of decision trees, combine multiple trees to improve accuracy and reduce overfitting.
5.3.2 Implementing Decision Trees and Random Forests
Implementing these models with Scikit-Learn involves similar steps:
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
# Decision Trees
tree_model = DecisionTreeClassifier()
tree_model.fit(X_train, y_train)
# Random Forests
forest_model = RandomForestClassifier()
forest_model.fit(X_train, y_train)5.4 Model Evaluation for Classification
5.4.1 Metrics for Classification
Evaluating classification models requires metrics that capture the nuances of predicting classes. Common metrics include:
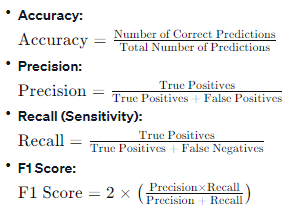
Conclusion
As we traverse the realm of classification techniques, from binary and multiclass classification to the power of SVM and the ensemble magic of Decision Trees and Random Forests, we equip ourselves with versatile tools for predictive categorization. Armed with the knowledge of implementation and evaluation metrics, you’re ready to navigate and excel in diverse classification scenarios. As we journey further into the landscape of machine learning, remember that classification lays the groundwork for solving a myriad of real-world problems. Happy classifying!
6. Clustering and Unsupervised Learning: Unveiling Patterns in Unlabeled Data
In the vast expanse of machine learning, unsupervised learning plays a crucial role in discovering patterns within data without explicit labels. In this section, we delve into the world of clustering, introducing the K-Means and Hierarchical Clustering algorithms. Additionally, we explore the concept of dimensionality reduction using Principal Component Analysis (PCA), providing a holistic understanding of unsupervised learning techniques.
6.1 K-Means Clustering
6.1.1 Unveiling Patterns with K-Means
K-Means is a versatile clustering algorithm that partitions data into ‘k’ clusters based on similarity. The algorithm iteratively assigns data points to clusters and updates cluster centroids until convergence.
6.1.2 Implementing K-Means with Scikit-Learn
Let’s implement K-Means clustering using Scikit-Learn:
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
# Assume X is your feature matrix
kmeans = KMeans(n_clusters=3)
kmeans.fit(X)
# Obtain cluster labels and centroids
labels = kmeans.labels_
centroids = kmeans.cluster_centers_
# Visualize the clusters
plt.scatter(X[:, 0], X[:, 1], c=labels, cmap='viridis')
plt.scatter(centroids[:, 0], centroids[:, 1], marker='X', s=200, color='red')
plt.title('K-Means Clustering')
plt.show()6.2 Hierarchical Clustering
6.2.1 Building Hierarchies with Hierarchical Clustering
Hierarchical Clustering creates a tree of clusters, allowing for a visual representation of relationships between data points. It can be agglomerative (bottom-up) or divisive (top-down).
6.2.2 Implementing Hierarchical Clustering with Scikit-Learn
Implementing hierarchical clustering involves linkage methods such as ‘ward’ or ‘complete’:
from sklearn.cluster import AgglomerativeClustering
import scipy.cluster.hierarchy as sch
# Assume X is your feature matrix
hc = AgglomerativeClustering(n_clusters=3, affinity='euclidean', linkage='ward')
labels = hc.fit_predict(X)
# Dendrogram for hierarchical clustering
dendrogram = sch.dendrogram(sch.linkage(X, method='ward'))
plt.title('Dendrogram')
plt.show()6.3 Dimensionality Reduction with PCA
6.3.1 Unleashing the Power of PCA
Principal Component Analysis (PCA) is a dimensionality reduction technique that transforms data into a lower-dimensional space while retaining its variance. It’s widely used for feature extraction and visualization.
6.3.2 Implementing PCA with Scikit-Learn
Apply PCA to reduce the dimensionality of your data:
from sklearn.decomposition import PCA
# Assume X is your feature matrix
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X)
# Visualize the reduced-dimensional data
plt.scatter(X_pca[:, 0], X_pca[:, 1], c='blue', alpha=0.5)
plt.title('Dimensionality Reduction with PCA')
plt.show()Conclusion
Unsupervised learning opens the door to understanding patterns in data without predefined labels. As we explore K-Means and Hierarchical Clustering for clustering and PCA for dimensionality reduction, we gain powerful tools for uncovering insights in various domains. Armed with the ability to implement and visualize these techniques, you’re well-equipped to explore the latent structures within your data. As we venture further into the landscape of machine learning, remember that unsupervised learning is the key to unlocking hidden patterns and relationships. Happy clustering!
7. Introduction to Neural Networks: Unraveling the Power of Artificial Intelligence
In the vast realm of machine learning, neural networks stand as a pinnacle of artificial intelligence, mimicking the human brain’s intricate structure. In this section, we embark on a journey through the fundamentals of neural networks, from understanding their basic architecture to building a simple neural network and delving into the world of deep learning with TensorFlow.
7.1 Basics of Neural Networks
7.1.1 The Neuron: Building Block of Neural Networks
At the core of neural networks lies the neuron, the fundamental unit inspired by its biological counterpart. Neurons process information through weighted inputs, applying an activation function to produce an output.
7.1.2 Layers and Activation Functions
Neural networks comprise layers, including an input layer, one or more hidden layers, and an output layer. Activation functions, such as sigmoid or ReLU, introduce non-linearity, enabling networks to learn complex patterns.
7.2 Building a Simple Neural Network
7.2.1 Implementing a Feedforward Neural Network
Let’s implement a simple feedforward neural network using a popular deep learning library, Keras:
from keras.models import Sequential
from keras.layers import Dense
# Assume X_train and y_train are your training data and labels
model = Sequential()
# Adding an input layer and a hidden layer
model.add(Dense(units=64, activation='relu', input_dim=X_train.shape[1]))
# Adding an output layer
model.add(Dense(units=1, activation='sigmoid'))
# Compiling the model
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
# Training the model
model.fit(X_train, y_train, epochs=10, batch_size=32, validation_data=(X_val, y_val))7.3 Deep Learning with TensorFlow
7.3.1 Unleashing the Power of TensorFlow
TensorFlow is a robust open-source machine learning library, extensively used for deep learning applications. It provides a flexible platform for building and deploying machine learning models.
7.3.2 Implementing Deep Learning with TensorFlow
Let’s implement a simple deep learning model using TensorFlow:
import tensorflow as tf
from tensorflow.keras import layers, models
# Assume X_train and y_train are your training data and labels
model = models.Sequential([
layers.Dense(64, activation='relu', input_shape=(X_train.shape[1],)),
layers.Dense(32, activation='relu'),
layers.Dense(1, activation='sigmoid')
])
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
model.fit(X_train, y_train, epochs=10, batch_size=32, validation_data=(X_val, y_val))Conclusion
Neural networks, with their ability to learn intricate patterns, mark a paradigm shift in machine learning. By understanding the basics, building simple models, and venturing into deep learning with TensorFlow, you unlock the potential to solve complex problems and make intelligent predictions. As we journey deeper into the world of artificial intelligence, remember that neural networks are the bedrock of cutting-edge applications, offering a glimpse into the limitless possibilities of machine learning. Happy coding!
8. Natural Language Processing (NLP): Decoding the Power of Textual Data
Natural Language Processing (NLP) stands at the forefront of machine learning, enabling computers to understand, interpret, and generate human language. In this section, we unravel the intricacies of NLP, from providing an overview of its capabilities to delving into text preprocessing techniques and building NLP models.
8.1 Overview of NLP
8.1.1 NLP’s Role in Language Understanding
NLP empowers machines to comprehend and respond to human language, bridging the gap between computers and human communication. Its applications range from sentiment analysis and language translation to chatbots and speech recognition.
8.1.2 Key NLP Tasks
NLP encompasses a myriad of tasks, including:
- Tokenization: Breaking text into smaller units (tokens).
- Part-of-Speech Tagging: Identifying grammatical parts of words.
- Named Entity Recognition (NER): Extracting entities like names, locations, and organizations.
- Sentiment Analysis: Determining the sentiment expressed in a piece of text.
8.2 Text Preprocessing
8.2.1 The Importance of Text Preprocessing
Before building NLP models, it’s crucial to preprocess text data. This involves:
- Tokenization: Splitting text into words or phrases.
- Lowercasing: Converting all text to lowercase for consistency.
- Removing Stopwords: Eliminating common words that don’t contribute much meaning.
- Stemming and Lemmatization: Reducing words to their base or root form.
8.2.2 Implementing Text Preprocessing with NLTK
Let’s implement basic text preprocessing using the Natural Language Toolkit (NLTK) in Python:
import nltk
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
from nltk.stem import PorterStemmer
nltk.download('stopwords')
nltk.download('punkt')
# Example text
text = "Natural Language Processing is fascinating!"
# Tokenization
tokens = word_tokenize(text)
# Lowercasing
lowercase_tokens = [token.lower() for token in tokens]
# Removing stopwords
filtered_tokens = [token for token in lowercase_tokens if token not in stopwords.words('english')]
# Stemming
stemmer = PorterStemmer()
stemmed_tokens = [stemmer.stem(token) for token in filtered_tokens]
print("Original Text:", text)
print("Processed Tokens:", stemmed_tokens)8.3 Building NLP Models
8.3.1 Leveraging Pretrained Models
NLP models often benefit from pretrained models like BERT or GPT-3. These models have learned patterns from massive datasets, making them powerful for various NLP tasks.
8.3.2 Fine-Tuning a Model with Hugging Face Transformers
Hugging Face Transformers simplifies working with pretrained models. Here’s a snippet for fine-tuning a model for sentiment analysis:
from transformers import BertTokenizer, BertForSequenceClassification, AdamW
from torch.utils.data import DataLoader, Dataset
# Assume you have a custom dataset for sentiment analysis
class CustomDataset(Dataset):
# Implement dataset class
# Tokenizer and model initialization
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertForSequenceClassification.from_pretrained('bert-base-uncased', num_labels=2)
# Fine-tuning
train_dataloader = DataLoader(train_dataset, batch_size=4, shuffle=True)
optimizer = AdamW(model.parameters(), lr=5e-5)
for epoch in range(3):
for batch in train_dataloader:
inputs = tokenizer(batch['text'], return_tensors='pt', padding=True, truncation=True)
labels = batch['label']
outputs = model(**inputs, labels=labels)
loss = outputs.loss
loss.backward()
optimizer.step()
optimizer.zero_grad()Conclusion
NLP unlocks the power of language in the realm of machine learning, enabling computers to comprehend and interact with textual data. From understanding the basics and preprocessing text to building NLP models, this section serves as a gateway to harnessing the potential of language-driven applications. As we journey deeper into the landscape of NLP, remember that every word processed and every model built brings us closer to machines that truly understand and respond to human language. Happy natural language processing!
9. Recommendation Systems: Guiding Users Through the Maze of Choices
In the vast landscape of online content and services, recommendation systems stand as indispensable tools, aiding users in discovering relevant and personalized items. In this section, we delve into the mechanics of recommendation systems, exploring collaborative filtering, content-based recommendation, and the synergy of hybrid recommendation systems.
9.1 Collaborative Filtering
9.1.1 The Essence of Collaborative Filtering
Collaborative filtering relies on user-item interaction data to make recommendations. It comes in two flavors:
- User-Based Collaborative Filtering: Recommends items based on the preferences of users with similar tastes.
- Item-Based Collaborative Filtering: Recommends items similar to those previously liked by a user.
9.1.2 Implementing Collaborative Filtering with Surprise
Let’s implement user-based collaborative filtering using the Surprise library in Python:
from surprise import Dataset, Reader, KNNBasic
from surprise.model_selection import train_test_split
# Assume you have a dataset with 'user', 'item', and 'rating' columns
reader = Reader(rating_scale=(1, 5))
data = Dataset.load_from_df(df[['user', 'item', 'rating']], reader)
trainset, testset = train_test_split(data, test_size=0.2)
# User-Based Collaborative Filtering
model = KNNBasic(sim_options={'user_based': True})
model.fit(trainset)
# Make predictions
predictions = model.test(testset)9.2 Content-Based Recommendation
9.2.1 Unveiling Content-Based Recommendation
Content-based recommendation relies on the characteristics of items and the preferences expressed by users. It recommends items similar to those the user has liked in the past.
9.2.2 Implementing Content-Based Recommendation with Scikit-Learn
Let’s implement content-based recommendation using the Tf-idf vectorizer and cosine similarity:
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import linear_kernel
# Assume you have a dataset with 'item' and 'description' columns
tfidf_vectorizer = TfidfVectorizer(stop_words='english')
tfidf_matrix = tfidf_vectorizer.fit_transform(df['description'])
# Calculate cosine similarity
cosine_sim = linear_kernel(tfidf_matrix, tfidf_matrix)
# Function to get recommendations
def get_recommendations(item_index, cosine_sim=cosine_sim):
sim_scores = list(enumerate(cosine_sim[item_index]))
sim_scores = sorted(sim_scores, key=lambda x: x[1], reverse=True)
sim_scores = sim_scores[1:6] # Get the top 5 most similar items
item_indices = [i[0] for i in sim_scores]
return df['item'].iloc[item_indices].tolist()
# Example: Get recommendations for item at index 0
recommendations = get_recommendations(0)
print(recommendations)9.3 Hybrid Recommendation Systems
9.3.1 Leveraging the Power of Hybrid Recommendation Systems
Hybrid recommendation systems combine collaborative filtering and content-based approaches to improve recommendation accuracy and overcome their individual limitations.
9.3.2 Implementing a Hybrid Recommendation System
Let’s implement a simple hybrid recommendation system using a weighted average approach:
# Assume you have predictions from collaborative filtering (CF) and content-based (CB) models
predictions_cf = model.test(testset)
predictions_cb = get_recommendations(0)
# Weighted average approach
weight_cf = 0.7
weight_cb = 0.3
hybrid_scores = {}
for uid, iid, true_r, est_cf, _ in predictions_cf:
est_cb = predictions_cb[iid] if iid in predictions_cb else 0
hybrid_scores[(uid, iid)] = weight_cf * est_cf + weight_cb * est_cb
# Get top recommendations
top_recommendations = sorted(hybrid_scores.items(), key=lambda x: x[1], reverse=True)[:5]
print(top_recommendations)Conclusion
Recommendation systems play a pivotal role in enhancing user experiences by providing personalized suggestions. From collaborative filtering to content-based recommendation and the synergistic power of hybrid recommendation systems, this section equips you with the tools to navigate the intricacies of recommendation algorithms. As we venture further into the landscape of personalized content delivery, remember that every recommendation made is a step toward creating a more tailored and engaging user journey. Happy recommending!
10. Model Deployment and Real-World Applications: Bridging the Gap Between Development and Impact
In the expansive field of machine learning, the ultimate goal is to turn models from mere code into impactful tools that solve real-world problems. This section guides you through the critical aspects of model deployment, showcases real-world applications, and addresses the challenges and best practices associated with deploying machine learning models.
10.1 Considerations for Model Deployment
10.1.1 Scalability and Performance
Consider the scalability of your model, ensuring it can handle increased workloads efficiently. Optimize its performance to deliver quick and accurate results, even under heavy usage.
10.1.2 Integration with Existing Systems
Successful deployment often involves integrating machine learning models seamlessly with existing systems and workflows. Compatibility with different frameworks and technologies is crucial.
10.1.3 Monitoring and Maintenance
Implement robust monitoring mechanisms to keep track of your model’s performance over time. Regular maintenance is essential to address issues, update models, and ensure continued relevance.
10.2 Real-World Applications of Machine Learning
10.2.1 Healthcare: Predictive Diagnostics
Machine learning models are revolutionizing healthcare by predicting diseases based on patient data. For example, models can predict the likelihood of a patient developing diabetes or identifying potential cancer risks.
10.2.2 Finance: Fraud Detection
In the financial sector, machine learning is employed to detect fraudulent activities. Models analyze transaction patterns and identify anomalies, helping financial institutions protect against fraudulent transactions.
10.2.3 E-Commerce: Personalized Recommendations
E-commerce platforms leverage machine learning to provide personalized product recommendations. Algorithms analyze user behavior and preferences to suggest items tailored to individual tastes.
10.2.4 Autonomous Vehicles: Computer Vision
Autonomous vehicles rely on machine learning, particularly computer vision, to navigate and make decisions in real-time. These models interpret sensor data, identify objects, and ensure safe driving.
10.3 Challenges and Best Practices
10.3.1 Data Privacy and Security
Protecting sensitive data is a paramount concern. Implement robust security measures to ensure data privacy and compliance with regulations like GDPR.
10.3.2 Interpretability and Explainability
Models that are too complex may lack interpretability, making it challenging to understand their decisions. Strive for models that are both accurate and interpretable for better trust and adoption.
10.3.3 Deployment Environment Variability
Real-world deployment environments may differ from the controlled development environment. Test your model in diverse scenarios to ensure its robustness and reliability.
10.3.4 Continuous Integration and Delivery (CI/CD)
Adopt CI/CD practices to streamline the deployment process. Automate testing, validation, and model updates to ensure a smooth and efficient deployment pipeline.
Conclusion
Deploying machine learning models is the culmination of the development journey, bringing the potential for impact and transformation to various industries. As we navigate the considerations for deployment, explore real-world applications, and tackle challenges with best practices, remember that the true value of machine learning lies in its ability to solve complex problems and make a positive difference in the real world. Happy deploying!
11. Advanced Topics and Emerging Trends: Exploring the Frontiers of Machine Learning
In the dynamic landscape of machine learning, continuous innovation leads to the emergence of advanced topics that push the boundaries of what’s possible. This section delves into three cutting-edge areas: Transfer Learning, Reinforcement Learning, and Generative Adversarial Networks (GANs).
11.1 Transfer Learning
11.1.1 Leveraging Pretrained Models
Transfer learning involves using knowledge gained from solving one problem to tackle a different but related problem. In the context of deep learning, pretrained models are a cornerstone of transfer learning.
11.1.2 Example with Image Classification
Let’s say you have a pretrained convolutional neural network (CNN) for image classification on a large dataset. You can repurpose this model for a different image classification task with a smaller dataset:
from tensorflow.keras.applications import VGG16
from tensorflow.keras import layers, models
# Load the pretrained VGG16 model
base_model = VGG16(weights='imagenet', include_top=False, input_shape=(224, 224, 3))
# Create a new model on top of the pretrained base
model = models.Sequential()
model.add(base_model)
model.add(layers.Flatten())
model.add(layers.Dense(256, activation='relu'))
model.add(layers.Dense(10, activation='softmax'))
# Train the model on the new task11.2 Reinforcement Learning
11.2.1 Learning Through Interaction
Reinforcement learning is a paradigm where an agent learns to make decisions by interacting with an environment. The agent receives feedback in the form of rewards or punishments based on its actions.
11.2.2 Example with Q-Learning
Consider a simple example of Q-learning, a foundational reinforcement learning algorithm, to teach an agent to navigate a grid-world:
import numpy as np
# Define the environment (grid-world)
environment = np.array([
[0, 0, 0, 0],
[0, -1, 0, -1],
[0, 0, 0, 0],
[-1, 0, 0, 1]
])
# Q-learning algorithm
Q = np.zeros_like(environment, dtype=np.float32)
gamma = 0.8 # Discount factor
alpha = 0.9 # Learning rate
for _ in range(1000):
state = np.random.randint(0, 16)
while state != 15: # Goal state
possible_actions = np.where(environment.flatten() != -1)[0]
action = np.random.choice(possible_actions)
next_state = np.where(environment.flatten() == action)[0][0]
reward = environment.flatten()[next_state]
Q[state // 4, state % 4] += alpha * (reward + gamma * np.max(Q[next_state // 4, next_state % 4]) - Q[state // 4, state % 4])
state = next_state11.3 Generative Adversarial Networks (GANs)
11.3.1 Unleashing Creative AI
Generative Adversarial Networks (GANs) are a class of machine learning models that can generate new data instances. They consist of a generator and a discriminator, trained in tandem.
11.3.2 Example with Image Generation
Consider an example using GANs to generate realistic images of handwritten digits:
from tensorflow.keras.models import Sequential, Model
from tensorflow.keras.layers import Dense, LeakyReLU, BatchNormalization, Reshape, Flatten
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.datasets import mnist
# Load and preprocess the MNIST dataset
(X_train, _), (_, _) = mnist.load_data()
X_train = (X_train.astype(np.float32) - 127.5) / 127.5
X_train = X_train.reshape(X_train.shape[0], 784)
# Build the GAN model
generator = build_generator()
discriminator = build_discriminator()
gan = build_gan(generator, discriminator)
# Train the GAN model
train_gan(generator, discriminator, gan, X_train)Conclusion
As we explore transfer learning, reinforcement learning, and generative adversarial networks (GANs), we glimpse the forefront of machine learning innovation. These advanced topics unlock new possibilities, from repurposing knowledge to interacting with dynamic environments and generating creative outputs. As we embrace the evolving landscape of machine learning, remember that these techniques pave the way for unprecedented applications and solutions. Happy exploring!
12. Practical Tips and Best Practices: Navigating the Realities of Machine Learning
In the dynamic realm of machine learning, practical tips and best practices can significantly impact the effectiveness of your models and your overall success. This section provides insights into effective model training, debugging and troubleshooting, and the importance of continuous learning in the ever-evolving field of machine learning.
12.1 Tips for Effective Model Training
12.1.1 Define Clear Objectives
Clearly define the objectives of your machine learning project. Understand the problem you are solving, the metrics you are optimizing, and the criteria for success.
12.1.2 Data Preprocessing is Key
Invest time in data preprocessing. Clean and normalize your data, handle missing values, and ensure it’s representative of the problem you’re solving.
12.1.3 Feature Engineering Matters
Crafting relevant features enhances model performance. Understand the domain and engineer features that provide meaningful insights for your models.
12.1.4 Split Your Data Thoughtfully
Separate your data into training, validation, and test sets. This helps you assess model performance on unseen data and avoid overfitting.
12.1.5 Experiment with Different Models
Explore various algorithms and architectures. Experimentation helps you identify the model that best suits your data and problem.
12.1.6 Regularization for Robustness
Incorporate regularization techniques like dropout or L1/L2 regularization to prevent overfitting and improve the generalization of your models.
12.2 Debugging and Troubleshooting
12.2.1 Embrace Logging and Visualization
Implement logging to capture important information during training and debugging. Visualization tools can provide insights into model behavior.
12.2.2 Check for Data Mismatch
Ensure consistency between training and deployment data. Mismatched data can lead to unexpected issues in real-world scenarios.
12.2.3 Inspect Model Predictions
Examine individual predictions to understand where your model succeeds and where it fails. This insight guides further improvements.
12.2.4 Monitor for Anomalies
Set up monitoring systems to detect anomalies in model behavior. Sudden changes may indicate issues or shifts in the data distribution.
12.2.5 Gradually Increase Model Complexity
When encountering issues, incrementally increase model complexity. This helps identify the point at which the model struggles or breaks.
12.3 Continuous Learning in the Field of Machine Learning
12.3.1 Stay Updated with Research
Regularly read research papers and publications to stay informed about the latest advancements and breakthroughs in machine learning.
12.3.2 Engage in Online Communities
Participate in online forums, communities, and discussions. Platforms like GitHub, Stack Overflow, and Kaggle offer valuable insights and collaboration opportunities.
12.3.3 Attend Conferences and Workshops
Attend conferences, workshops, and meetups to connect with experts and enthusiasts. These events provide networking opportunities and exposure to diverse perspectives.
12.3.4 Contribute to Open Source Projects
Contribute to open source projects to gain hands-on experience, collaborate with the community, and showcase your skills.
12.3.5 Pursue Continuous Education
The field of machine learning evolves rapidly. Pursue continuous education through courses, certifications, and specialized training to stay relevant.
Conclusion
In the ever-evolving landscape of machine learning, practical tips and best practices serve as guiding principles for success. From effective model training to debugging and troubleshooting, and the commitment to continuous learning, these practices empower you to navigate challenges and harness the full potential of machine learning. As you embark on your machine learning journey, remember that adaptability and a willingness to learn are key to thriving in this dynamic field. Happy learning and modeling!
13. Conclusion: Reflecting on the Journey of Machine Learning Mastery
As we reach the conclusion of this comprehensive exploration into the realm of machine learning, let’s take a moment to recap key concepts and provide encouragement for further exploration. This journey has covered a diverse array of topics, from foundational principles to advanced techniques, offering a holistic view of the machine learning landscape.
13.1 Recap of Key Concepts
13.1.1 Foundational Principles
We began our journey by laying the foundation of machine learning, understanding its core concepts, types, and the fundamental algorithms that underpin this transformative field.
13.1.2 Practical Skills and Techniques
Delving into practical skills, we explored data preprocessing, feature engineering, model evaluation, and optimization techniques. Hands-on learning through Python and popular libraries like Scikit-Learn and TensorFlow enriched our toolset.
13.1.3 Advanced Topics and Emerging Trends
Venturing into advanced topics, we navigated transfer learning, reinforcement learning, and the fascinating world of Generative Adversarial Networks (GANs). These cutting-edge areas exemplify the ongoing innovation in machine learning.
13.1.4 Real-World Applications
Examining real-world applications showcased how machine learning transforms diverse industries, from healthcare and finance to e-commerce and autonomous vehicles. The practical impact of machine learning on solving complex problems is profound.
13.1.5 Best Practices and Continuous Learning
Practical tips, best practices, and the importance of continuous learning were emphasized. These insights provide a roadmap for effective model training, debugging, and troubleshooting, while the commitment to continuous education ensures relevance in a rapidly evolving field.
13.2 Encouragement for Further Exploration
13.2.1 Embrace Curiosity and Experimentation
Machine learning is a dynamic field where curiosity and experimentation thrive. Encourage yourself to explore new algorithms, experiment with diverse datasets, and embrace the joy of discovery.
13.2.2 Connect with the Community
Join the vibrant machine learning community through online forums, conferences, and collaborative platforms. Engaging with fellow enthusiasts and experts opens avenues for learning, collaboration, and mentorship.
13.2.3 Apply Machine Learning to Real-World Problems
Take your newfound knowledge and apply it to real-world problems. The true measure of mastery is the ability to leverage machine learning to create meaningful solutions that positively impact society.
13.2.4 Stay Informed and Adapt
Machine learning is a field that evolves rapidly. Stay informed about the latest research, technologies, and trends. Adaptability and a growth mindset are essential for success in this dynamic landscape.
13.2.5 Celebrate Progress and Persevere
Celebrate your progress, both big and small. Machine learning is a journey of continuous improvement. Persevere through challenges, learn from failures, and relish the satisfaction of overcoming obstacles.
Final Thoughts
As we conclude this exploration of machine learning mastery, remember that the journey doesn’t end here—it transforms into a perpetual quest for knowledge and innovation. Whether you’re a novice taking the first steps or an experienced practitioner seeking deeper insights, the world of machine learning offers boundless opportunities for growth and impact. May your journey be filled with curiosity, discovery, and the fulfillment that comes from leveraging machine learning to create a better, smarter world. Happy exploring!

Maintenance, projects, and engineering professionals with more than 15 years experience working on power plants, oil and gas drilling, renewable energy, manufacturing, and chemical process plants industries.










